PLEASE NOTE: This article has been archived. It first appeared on ProRec.com in June 1998, contributed by then Editor-in-Chief Rip Rowan. We will not be making any updates to the article. Please visit the home page for our latest content. Thank you!
The most challenging tools for newcomers to the recording scene to understand are dynamics processors: compressors, expanders, noise gates and limiters. We are all familiar with tools like EQ, reverbs, choruses, flangers — even if we don’t know exactly how they work exactly we might understand what kinds of sounds they produce. Compressors are completely different animals because they work on the musical dynamics and their effects can range from undetectable to utterly bad.
What, then, are “dynamics” exactly?
Technically, dynamics refers to the variabilities in amplitudes. “Dynamic” material is said to have lots of variability in the amplitude of the audio.
There is a relationship between dynamics and loudness. Loudness (usually) refers to the average amplitude of a track. Green Day is LOUD! Dynamic refers to the variability – the difference between the soft and loud passages. The Beatles’ Abbey Road is dynamic.
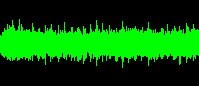
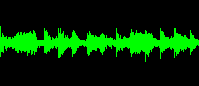
Note that while the peaks of each audio sample reach the same amplitude, the average volume of the Green Day sample is much higher than the Beatles sample, resulting in a “denser” looking waveform. Assuming the music is recorded using the media’s full dynamic range, it is impossible to make music simultaneously louder and more dynamic.
Often when a musician wants the track to be “louder” what they are really saying is to “make it more dynamic” because a dynamically squashed track doesn’t cut through – while one with good dynamics “peeks through the mix.” On the other hand – they might be saying “make it less dynamic” if certain parts or notes cut through but the overall track is too quiet. The engineer has to make a value judgment as to which way the dynamics need to go.
So, what compressors do is alter the dynamic content of the program material. They do this by leaving the quiet parts untouched, and by reducing the amplitude of the loud parts. The result is that the difference between the loud and quiet parts is lessened, and thus the track’s dynamics are reduced. By lowering the dynamics, the overall track can be boosted, and thus the track is made louder. This is the basic function of a compressor, but far more sophisticated results can be achieved.
Typically compressors have six controls:
1. Input Gain is just a pre-effect volume knob. Turning this up boosts the signal going into the compressor.
2. Threshold is the level at which the compressor starts reducing the volume. The knob typically works in reverse: with the knob all the way counterclockwise, the threshold is high, meaning that no matter how loud the signal is the compressor will not change the sound’s volume. As you turn the threshold clockwise, the threshold is lowered. Lower peaks will trigger the volume reduction effect.
3. Ratio refers to the how much the volume will be reduced. A ratio of 2:1 means that the part of the wave that crosses the threshold will have thier volume reduced by a factor of two. A ratio of 5:1 means that these peaks will have their volume reduced by a factor of five.
4. Attack refers to the length of time that the compressor will wait before reducing the volume. Setting a higher attack value lets more of the peak through before attenuation begins.
5. Release refers to the length of time before the compressor allows the volume to return to normal.
6. Makeup is a post-compressor gain. After the volume of the peaks is reduced, the track’s volume probably needs boosting.
These six effects can offer a fantastic amount of modification over the sound. Let’s look at what you can do with some basic compressor operations.
Say, for instance, that your bass track is a little uneven. Some notes pop right out, but others aren’t cutting through Your track looks something like this:

There are five notes shown. Notes 2 and 3 are clearly louder than the others, and note 5 is very quiet. You have already used EQ to try to fix the problem but the volume fluctuation doesn’t seem related to the frequency. In short, you have a lousy bass player. Well, you can’t polish a turd into a diamond, but maybe it doesn’t have to stink so badly. Try a little compression:
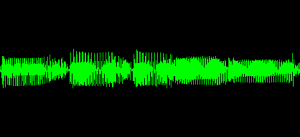
Wow! It even LOOKS better! I used a heavy compressor to make the effect obvious on the screen: threshold -25 db, ratio 10:1, attack 10 ms, release 40 ms. This is extreme, but you might want a compressor this extreme to make up for really bad bass playing. You can’t make it perfect, but at least the volume won’t be jumping around in the mix. This will fix the problem of certain notes jumping out too loud or certain notes not being audible. The result is a smoother, fatter bass sound.
Compressors can leave some wreckage in their path, however. Look at the first (uncompressed) signal. Note the “burp” between notes 2 and 3. That’s string noise – a sort of “click-bump.” See how much LOUDER it is in the compressed version? It was inaudible before, but now it shows up in the mix. Perhaps less compression would do the trick.
I always use at least some compression on vocals. A little compression can help to bring out the breath in a soft vocal. A tough vocal, with a loud vocalist, can benefit from heavier, harder compression, to take the edge off of loud, screaming parts. Using compression on a vocal, like any other instrument, can help it to “sit” in the mix – always audible, never too loud. With a good compressor properly tuned, the vocalist can go from whisper to scream and the whisper isn’t too soft – and the scream isn’t too loud.
So that’s how to use compression to make parts “sit” nicely in a mix. One of the things that used to confuse me was how an engineer would use compression to make parts “bite” or “jump out” in a mix. After all, if compressors reduce peaks and make the volume more level, what’s doing the “jumping out?”
The trick is the attack control. Remember the attack lets a certain amount of signal pass through uncompressed before volume reduction begins. If a track isn’t “biting” then it doesn’t have enough attack. You can use the compressor to add attack to a part.
Here’s a guitar part that was just downright “mushy”. It had almost no attack:
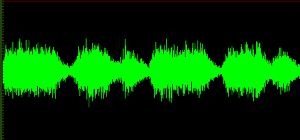
Note that, with the exception of the 3rd note, there is no difference in volume between the attack (initial part of the wave) and the rest of the note. These notes just sort of “wash” into the air with no announcement.
So I used a compressor, about a 5:1 ratio, threshold of -20 db, attack of 50 ms, release of 10 ms to produce this:

The five lines indicate the improvement in attack. Since note 3 already had attack it didn’t seem to change much, but there was a definite improvement in the other notes. Now, when this track is played back in the mix, you can actually hear the guitarist hitting the strings, instead of getting just a wash of sound.
So, in this example, we used a compressor to actually INCREASE the dynamics of the track instead of decreasing the dynamics! Pretty cool, huh?
Now you know the basics of compression: what it does, how it works, and some of the very basic things you can do with one. Next month, we’ll explain other dynamics processors: multiband compressors, noise gates, expanders, and limiters. And in Part Three in August we’ll explore and review different software compressor offerings from Waves, Syntrillium, Sonic Foundry, and others. Stay tuned!


