Introduction
This article will look at two elements: transcription which is the conversion of audio to text and converting text to speech. Transcription is beneficial for documentation. Looking at the transcription history you will notice that it has been around since ancient times. People used to transcribe languages or words to tablets and later on to scrolls as a form of documentation of happenings.
Recommended Read: Isolating and Autotuning Vocals in Adobe Audition
Transcription has grown and transitioned over the years to a point where it is a career and quite rewarding to an experienced typist. From there we have seen efforts to have artificial intelligence do and perfect it as it is sometimes a labor-intensive activity. Transcription is also useful to journalism by minimizing the usage of notebooks in this profession.
Converting text to speech, which will also be covered in this article is a growing market. In an audio editing career, I often use it in exercises like making tutorials. Others like software developers and instructional designers find it useful as well. Both of these topics are covered in this article with a focus on their performance and relation to Adobe Audition.
Transcribing (Speech to Text) in Adobe Audition

Adobe does not have a standalone transcription feature. It can convert text to speech which is addressed in the next section but cannot solely convert speech to text.
Being an application that would be the default or the go-to software for a number of podcasters. I feel like it will be an essential feature to be added. I am certain that you have seen promotional videos for podcasts with captions on them, whether on TikTok or Instagram. Transcription makes the editing of these videos easier. Hopefully, this feature will be included soon.
But for now, Adobe Audition can be integrated with Sonix to help you with some transcription work. Although, it is an application geared toward editing your audio using AI-generated text you can copy and paste the text into another document file. Here is a quick description of how your transcription process will be with Sonix. Open an audio file in Sonix and convert the speech to text. Make edits if need be. If you delete a word, the word will be removed from the audio. You can also remove words by using a strikethrough feature. Note that these edits are non-destructive.
Sonix timestamps all of the edits made. Timestamping exists in Adobe Audition in the name of Markers. Once you are done editing it, you can download the session in form of an Adobe Audition multitrack session file – SESX. After you open it in Audition, check your markers panel. Below is an image of how information is usually broken down.
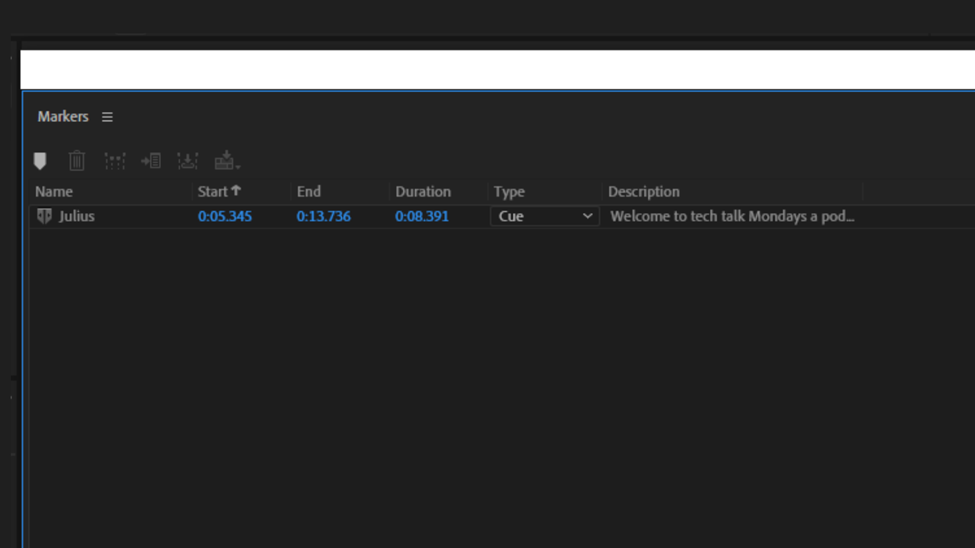
In the transcri[ption process in Sonix you can fill in the name of your speaker. This name will appear in Adobe as shown in the image above – Julius. The start and end indicate when the speaker started and ended the speech. The description has the text of the speech. To get the transcription, double-click the text under Description. Copy and paste it into a new document. Sonix only has 30 minutes of free transcription. If you intend to transcribe more minutes you will have to pay. Check the pricing HERE
Here is an alternative that you can use when you want to convert a piece of audio into text. This is Descript. Descript is standalone and you don’t need to integrate it with Audition. Also, its process is quite straightforward. Descript can be used on the web as well as an application for download. It completes the transcription of short audio files in just a few minutes. It is reliant on an internet connection and if you plan to use it extensively you will have to pay. The free plan only gives you a free 3-hour transcription per month. This is a resourceful option as you get lots of other key features apart from transcribing.
Text to Speech in Adobe Audition (Detailed Guide)
Here is a guide to converting text to computer-generated speech.
Once Adobe is running, click on Effects. From the list hover your mouse pointer over the Generate option. From this new list click on Speech.
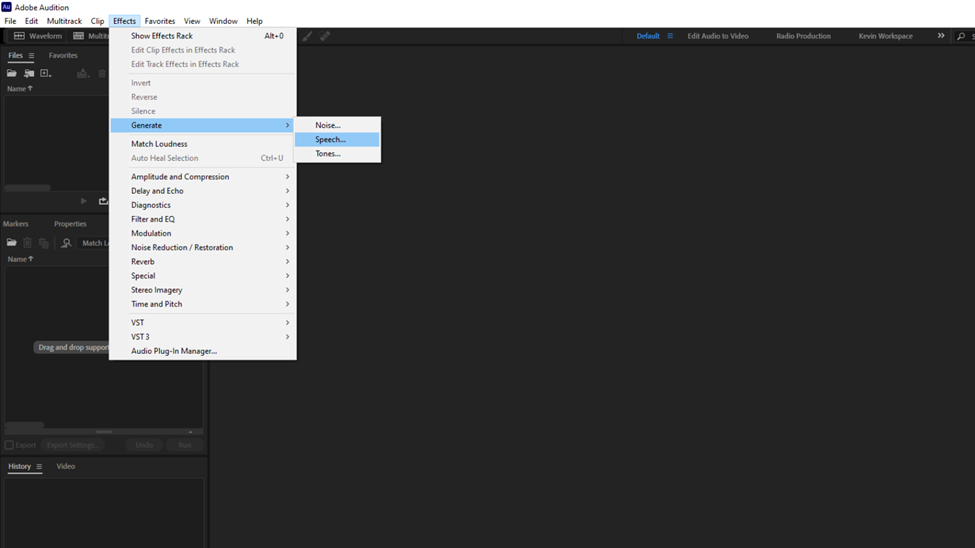
This will open a new audio dialogue box. Type in how you intend to name the audio then press OK.
This process will open a new dialogue box shown below.
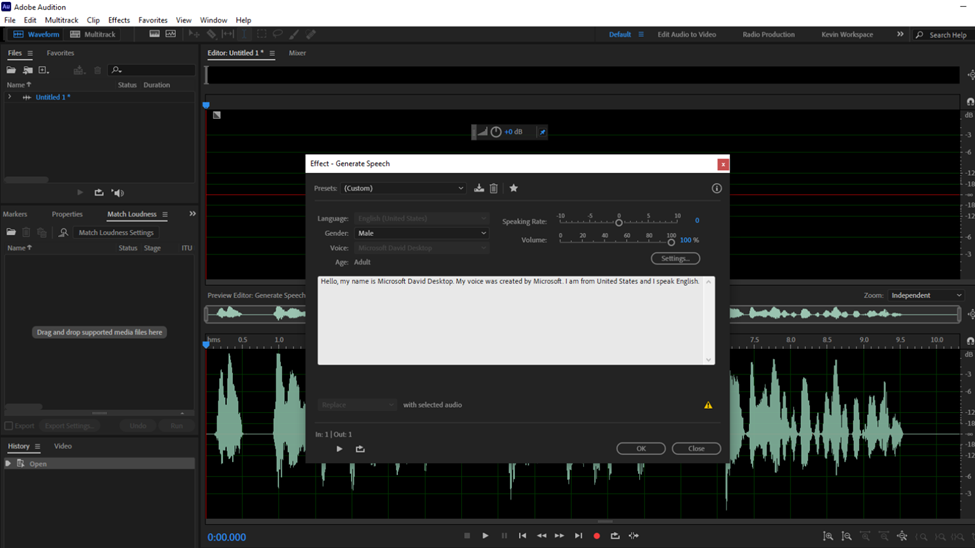
Before getting to the text box here are a few settings and slots to look at.
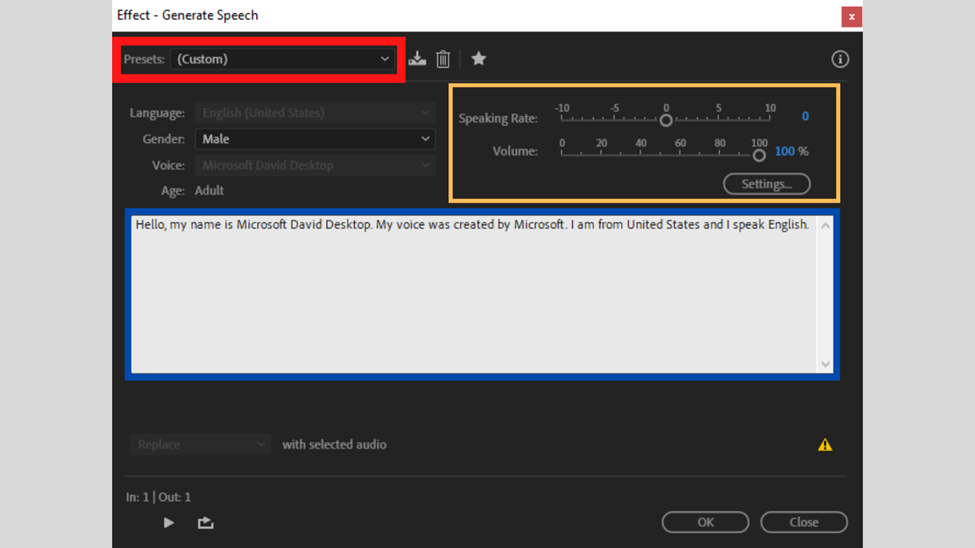
The first slot is highlighted with a red box. This is the presets entry that allows you to pick whose voice you are going to use. There are two options: Microsoft David Desktop – English (United States) and Microsoft Zira Desktop – English (United States)
In the next setting, the yellow highlighted one you can make adjustments to how fast and how loud you want the audio to sound with the Speaking Rate and Volume sliders respectively. Below these sliders, there is a Settings button that redirects you to the speech properties settings of your PC. The settings on this dialogue box match the ones on your computer. Therefore no need to use this button.
Lastly, the highlighted blue section is where you type the text that you need to be converted to audio. Anytime you launch this dialogue box there will be the text in the image above. For your changes to apply, select all, clear the text, type your text, and press play. Do not close the box as Adobe allows you to make changes and preview with the dialogue box being active.
Like many other text-to-audio generators you can use punctuations to add intonations to the statements. Also, sticking to the execution, the AI records any text written in the text box. This does not mean that the voice will perfectly execute German or Chinese texts. Statements with foreign words in English – loanwords – or non-English words will not be properly executed.
Conclusion
Whenever you use built-in voices for Adobe Audition and just in any other software always put into consideration licensing issues, you will not always be having unlimited usage of such voices with factors like commercialization.
With the advancement of AI, I have a strong conviction that Adobe Audition can Massively improve its speech generator process. With this, I am talking about elements like adding emotions like happiness or anger to the voice. I also believe that they can go to the extent of having multiple voice changes which will allow editors to make a conversational recording where voices change from one voice to another.
Regarding the lack of audio-to-text feature addressed earlier on I would say that it is long overdue. A layman would argue that since it is a digital audio workstation why do you need such a feature? I also believe it is a question that some audio editors who are starting out will ask as well. DAWs are known for recording, editing, and producing audio files. Transcription is very useful to filmmakers, video documentarians, podcasters, multimedia producers, and other professionals.

![Adobe Audition Razor Tool Greyed Out [FIXED]](https://ProRec.com/wp-content/uploads/2022/08/image-179-180x180.png "Adobe Audition Razor Tool Greyed Out [FIXED]")


{kind=link}